

The big AI news of the year was set to be OpenAI’s Stargate Project, announced on January 21. The project plans to invest $500 billion in AI infrastructure to “secure American leadership in AI.” One day before, a little-known Chinese AI company released its seventh major large language model to little acclaim. However, in the weeks since, the LLM changed the AI landscape (currently dominated by ChatGPT) and forced big players like OpenAI to reevaluate their business strategies.
Related
Gemini Advanced: Everything you need to know about Google’s premium AI
Google’s premium AI explained
What is DeepSeek?
Let’s start with the basics

Source: tv.CCTV.com
DeepSeek is a Chinese AI company founded by Liang Wenfang, co-founder of a successful quantitative hedge fund company that uses AI to inform its investment decisions. In 2023, Liang started DeepSeek as a side project to pursue artificial general intelligence, but this is more than the lark of an eccentric millionaire.
Liang began building his own data center in 2015 with 100 graphics cards. He opened Fire-Flyer 1 in 2019 with 1,100 cards and a $30 million investment. After dropping $140 million, he launched Fire-Flyer 2 in 2021 using 10,000 Nvidia A100 graphics cards (40GB–80GB, ≥1TB/s, ~$10,000/unit). Then, he decided to get serious about this AI business and created DeepSeek.
What did DeepSeek do before 2025?
Liang didn’t waste time. Less than six months after DeepSeek was a thing, it released DeepSeek-Coder and DeepSeek-LLM in November 2023. DeepSeek-MoE was released in January 2024, using a “mixture-of-experts” architecture that makes its current model popular and powerful.
In May last year, the world saw how disruptive this quiet Chinese company could be. DeepSeek released its V2 model with tokens priced so low that it triggered a price war within China, forcing companies like Alibaba, ByteDance, and Tencent to slash prices to keep pace. On the day after Christmas 2024, seven months after the release of V2, DeepSeek released V3. That’s where DeepSeek’s story in the current news cycle kicks off.

Related
Learn what ChatGPT is, how it works, what you can do with it, and how much it costs to use OpenAI’s most advanced AI chatbot
What are DeepSeek-V3 and DeepSeek-R1?
And why are they shaking up the industry so much?
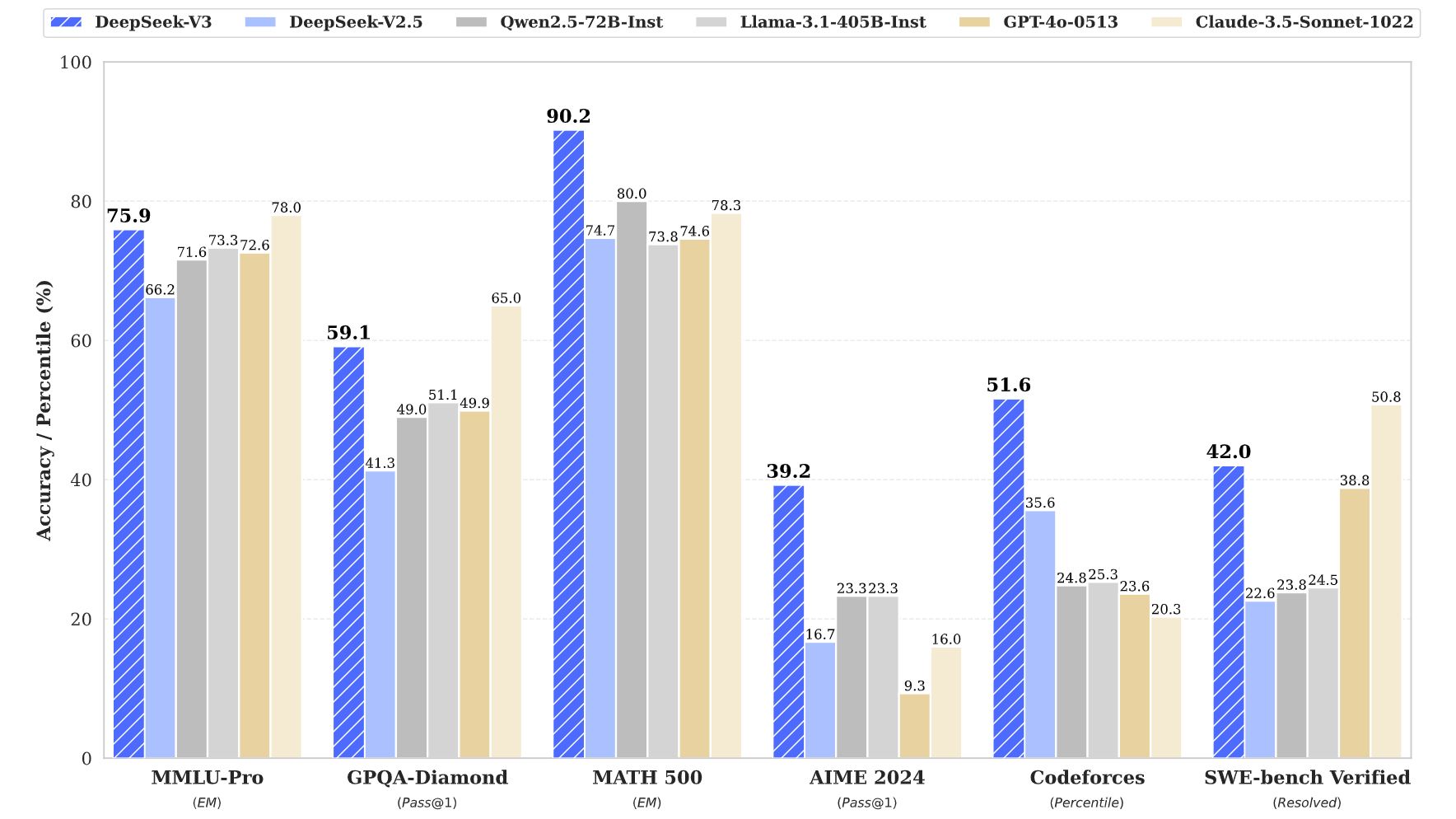
DeepSeek-V3 is a big, general-purpose language model that performs slightly better than GPT-4o and other leading LLMs on most benchmarks. V3 being slightly better than 4o (which has some neat tricks V3 doesn’t) doesn’t seem like big news, considering the AI industry has been in an arms race since OpenAI’s GPT-3 showed up in 2020. It’s the conditions under which V3 outperforms 4o that are noteworthy.
First, even though V3 was trained with 671 billion parameters, DeepSeek claims the cost of training this model was around $6 million (based on 2.788 million training hours on H800 GPUs at $2 per GPU hour, which is about the market rate). OpenAI CEO Sam Altman once quipped that GPT-4 (GPT-4o’s predecessor) cost over $100 million. The difference in training costs for two similarly powered models is so stark that it has shaken the market.
Source: DeepSeek/GitHub
Further, V3 uses a mixture-of-experts architecture, meaning it doesn’t activate all of its 671 billion parameters for each query. It only uses about 37 billion of them. That equates to faster responses and a lower computational cost per query, allowing DeepSeek to charge less for its tokens. OpenAI charges $2.50 per million input tokens and $10 per million output tokens on its GPT-4o model. DeepSeek charges $0.14 per million input tokens and $0.28 per million output tokens. The price difference is staggering.
|
Price per million tokens |
Input |
Output |
|---|---|---|
|
DeepSeek-V3 |
$0.14 |
$0.28 |
|
GPT-4o |
$2.50 |
$10.00 |
Why is DeepSeek-R1 a big deal?
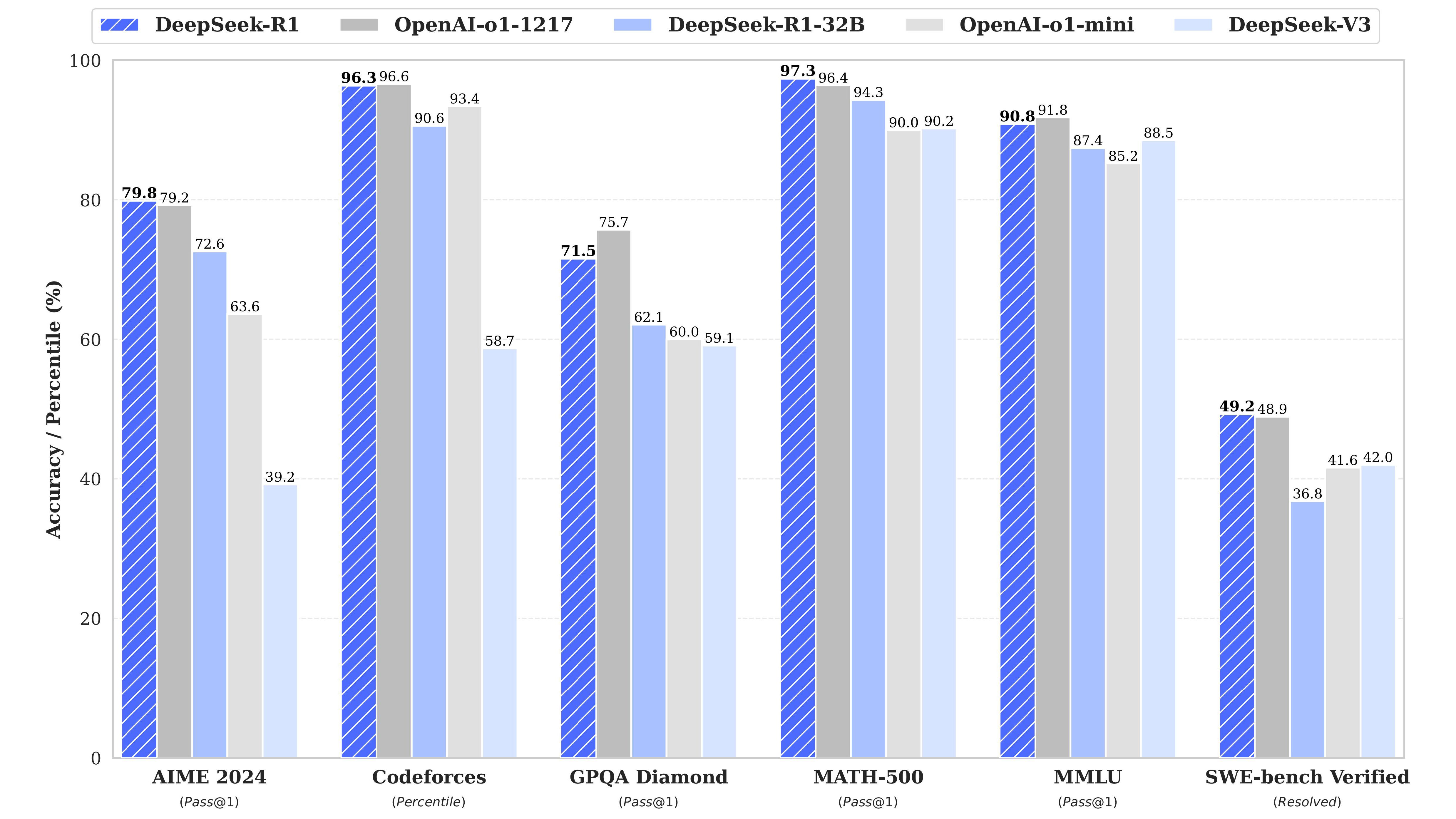
DeepSeek’s R1 model is built on the back of the previous V3 model and specializes in reasoning, a sort of internal monologue for LLMs (also known as chain of thought). What makes R1 interesting is that it was initially made exclusively using reinforcement learning with no supervised learning.
Supervised learning is a machine learning technique that teaches the model using labeled pairs of inputs and outputs. Reinforcement learning eschews labels and rewards the model as it gets closer to the desired outputs.
Source: DeepSeek/GitHub
The initial model made from this reinforcement-only technique is R1-Zero, and it developed emergent reasoning capabilities. It didn’t need to be trained to have an internal monologue. It just happened. The problem with R1-Zero was that it wasn’t very comprehensible despite its high benchmark scores. DeepSeek resolved this issue by fine-tuning the model with limited supervised learning, leading to R1, which could match OpenAI’s o1 reasoning model on numerous benchmarks while undercutting OpenAI’s prices.
|
Price per million tokens |
Input |
Output |
|---|---|---|
|
DeepSeek-R1 |
$0.14–$0.55 |
$2.19 |
|
OpenAI-o1 |
$7.50–$15.00 |
$60.00 |
DeepSeek is not the end of OpenAI (or Llama, or Gemini, or Anthropic)
The AI arms race is only just beginning
The market consequences of DeepSeek releasing R1 weren’t felt for a few days, but when it reacted, the market reacted big. The Nasdaq index saw a loss of $1 trillion in market capitalization. Nvidia had it worse than anyone, losing nearly $600 billion. How could DeepSeek trigger this kind of reaction?

DeepSeek matched the best that OpenAI had released, using cheaper hardware (like these awesome budget phones) for less training time, calling into question the necessity for big data centers and expensive GPUs. After all, why invest $100 million in training a new model with expensive hardware when $6 million and cheaper silicon is just as good? DeepSeek’s models won’t replace the American AI giants nor obviate the need for advanced processors. The markets have nearly recovered from last month’s crash, indicating that the AI industry is quickly returning to business as usual.
But don’t think that there hasn’t been a sea change. DeepSeek’s new models have proven that change can come from smaller players exploring new techniques. Because DeepSeek open sourced how it made its models, everyone is free to replicate its methods to make their models better.
That’s already happening. A team from Berkeley applied DeepSeek’s reinforcement learning algorithm to train the Qwen 3B model to solve simple math puzzles. For $30 of processing time, the same chain-of-thought reasoning present in the R1-Zero model emerged in their specialized model, indicating that the emergent reasoning reported by DeepSeek isn’t just an empty boast. In other words, look for more big players to use these training techniques pioneered by DeepSeek and released to the public.
The AI arms race is heating up
Rather than steal the thunder of major AI firms, DeepSeek injected new wind into the industry’s sails. More than demonstrating that innovation can come from smaller players and older hardware, it’s shown how much more its better-funded competitors (like Gemini and ChatGPT) are capable of given these new tricks. Last year was a hot year for AI, but don’t expect 2025 to cool down.

{kind=link}