

Multimodal output opens up new possibilities
Having true multimodal output opens up interesting new possibilities in chatbots. For example, Gemini 2.0 Flash can play interactive graphical games or generate stories with consistent illustrations, maintaining character and setting continuity throughout multiple images. It’s far from perfect, but character consistency is a new capability in AI assistants. We tried it out and it was pretty wild—especially when it generated a view a photo we provided from another angle.
Creating a multi-image story with Gemini 2.0 Flash, part 1.
Google / Benj Edwards
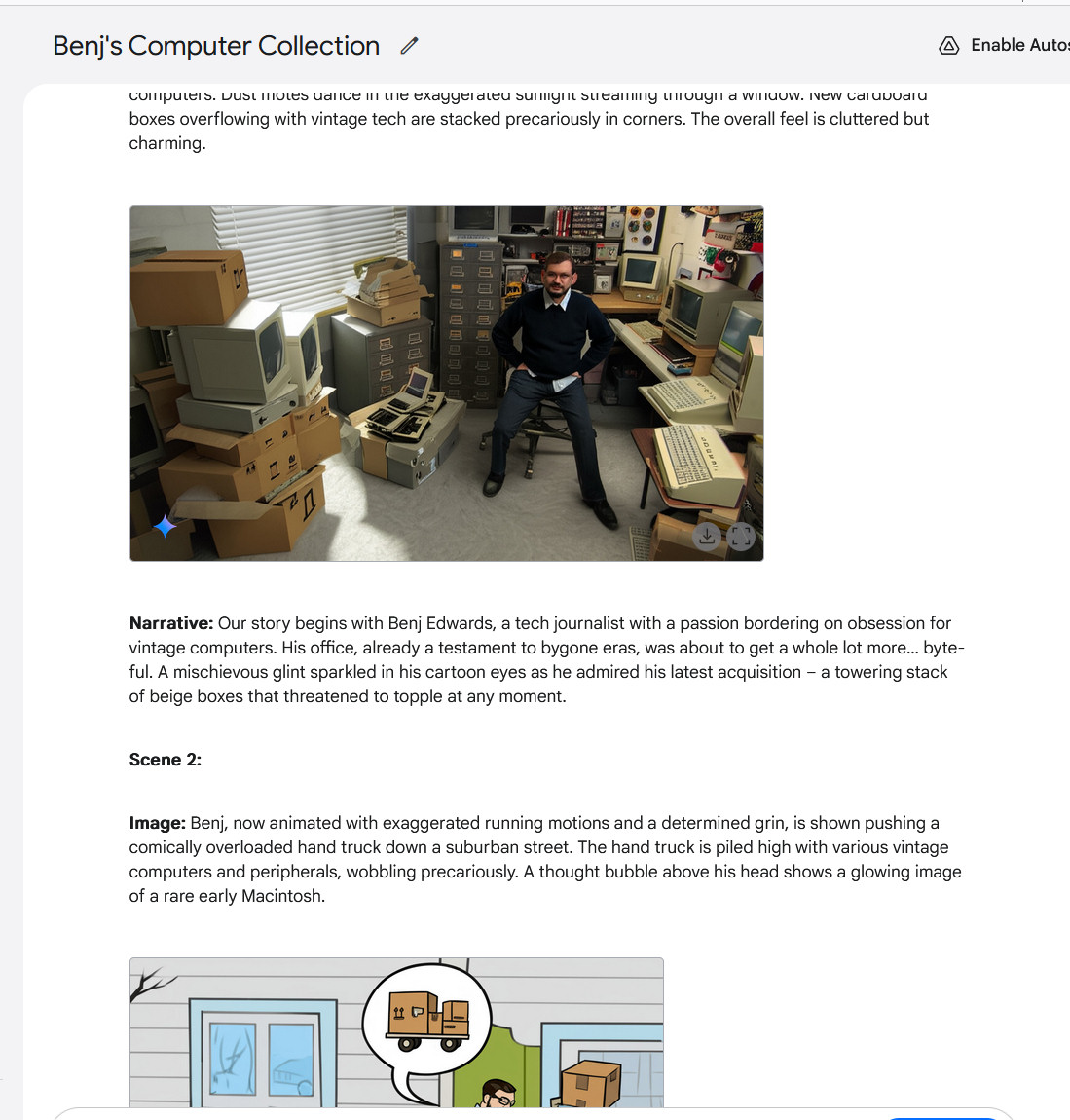
Google / Benj Edwards
Creating a multi-image story with Gemini 2.0 Flash, part 2. Notice the alternative angle of the original photo.
Google / Benj Edwards
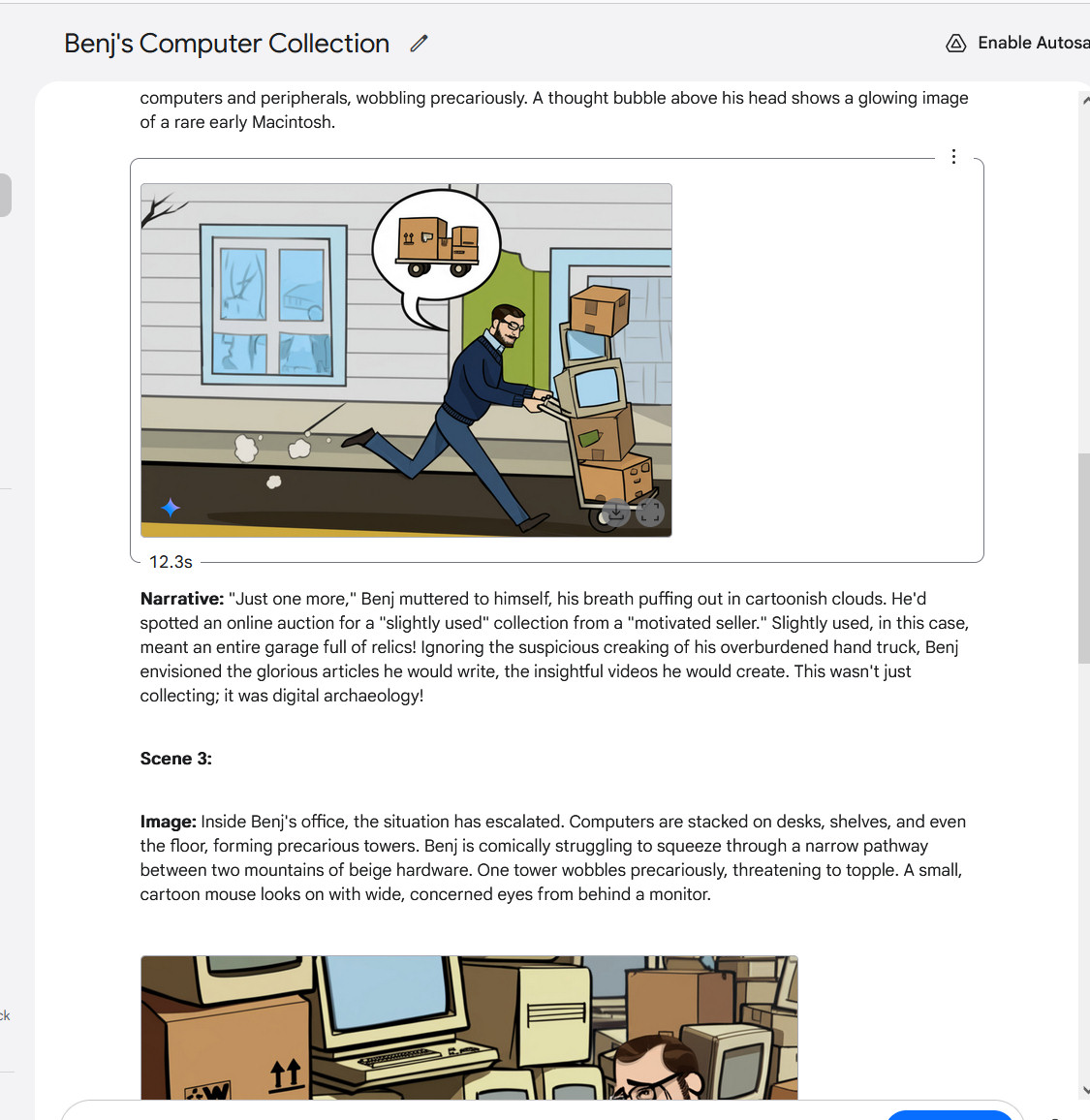
Google / Benj Edwards
Creating a multi-image story with Gemini 2.0 Flash, part 3.
Google / Benj Edwards
Creating a multi-image story with Gemini 2.0 Flash, part 2. Notice the alternative angle of the original photo.
Google / Benj Edwards
Creating a multi-image story with Gemini 2.0 Flash, part 3.
Google / Benj Edwards
Text rendering represents another potential strength of the model. Google claims that internal benchmarks show Gemini 2.0 Flash performs better than “leading competitive models” when generating images containing text, making it potentially suitable for creating content with integrated text. From our experience, the results weren’t that exciting, but they were legible.
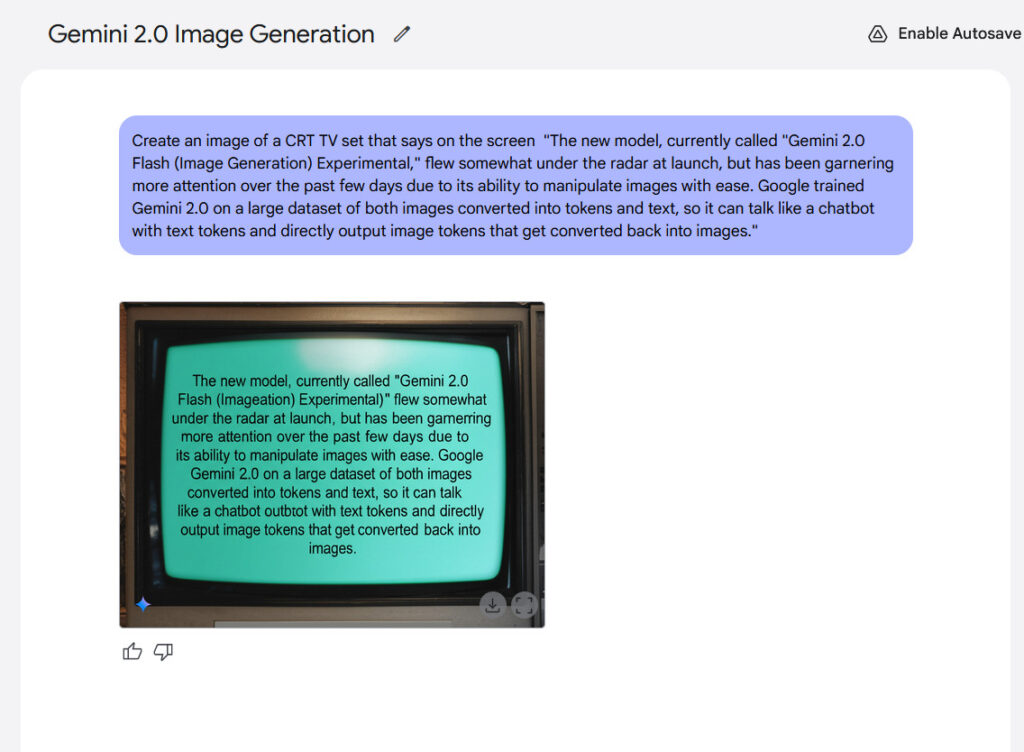
An example of in-image text rendering generated with Gemini 2.0 Flash.
Credit:
Google / Ars Technica
Despite Gemini 2.0 Flash’s shortcomings so far, the emergence of true multimodal image output feels like a notable moment in AI history because of what it suggests if the technology continues to improve. If you imagine a future, say 10 years from now, where a sufficiently complex AI model could generate any type of media in real time—text, images, audio, video, 3D graphics, 3D-printed physical objects, and interactive experiences—you basically have a holodeck, but without the matter replication.
Coming back to reality, it’s still “early days” for multimodal image output, and Google recognizes that. Recall that Flash 2.0 is intended to be a smaller AI model that is faster and cheaper to run, so it hasn’t absorbed the entire breadth of the Internet. All that information takes a lot of space in terms of parameter count, and more parameters means more compute. Instead, Google trained Gemini 2.0 Flash by feeding it a curated dataset that also likely included targeted synthetic data. As a result, the model does not “know” everything visual about the world, and Google itself says the training data is “broad and general, not absolute or complete.”
That’s just a fancy way of saying that the image output quality isn’t perfect—yet. But there is plenty of room for improvement in the future to incorporate more visual “knowledge” as training techniques advance and compute drops in cost. If the process becomes anything like we’ve seen with diffusion-based AI image generators like Stable Diffusion, Midjourney, and Flux, multimodal image output quality may improve rapidly over a short period of time. Get ready for a completely fluid media reality.

{kind=link}